How to Integrate DrissionPage with CapSolver for Seamless CAPTCHA Solving

Lucas Mitchell
Automation Engineer

1. Introduction
Web automation has become essential for data collection, testing, and various business operations. However, modern websites deploy sophisticated anti-bot measures and CAPTCHAs that can halt even the most carefully crafted automation scripts.
The combination of DrissionPage and CapSolver provides a powerful solution to this challenge:
- DrissionPage: A Python-based web automation tool that controls Chromium browsers without requiring WebDriver, combining browser automation with HTTP requests
- CapSolver: An AI-powered CAPTCHA solving service that handles Cloudflare Turnstile, reCAPTCHA and more
Together, these tools enable seamless web automation that bypasses both WebDriver detection and CAPTCHA challenges.
1.1. Integration Objectives
This guide will help you achieve three core goals:
- Avoid WebDriver Detection - Use DrissionPage's native browser control without Selenium/WebDriver signatures
- Automatically Solve CAPTCHAs - Integrate CapSolver's API to handle CAPTCHA challenges without manual intervention
- Maintain Human-Like Behavior - Combine action chains with intelligent CAPTCHA solving
2. What is DrissionPage?
DrissionPage is a Python-based web automation tool that combines browser control with HTTP request capabilities. Unlike Selenium, it uses a self-developed kernel that doesn't rely on WebDriver, making it harder to detect.
2.1. Key Features
- No WebDriver Required - Controls Chromium browsers natively without chromedriver
- Dual Mode Operation - Combine browser automation (d mode) with HTTP requests (s mode)
- Simplified Element Location - Intuitive syntax for finding elements
- Cross-iframe Navigation - Locate elements across iframes without switching
- Multi-tab Support - Operate multiple tabs simultaneously
- Action Chains - Chain mouse and keyboard actions together
- Built-in Waits - Automatic retry mechanisms for unstable networks
2.2. Installation
bash
# Install DrissionPage
pip install DrissionPage
# Install requests library for CapSolver API
pip install requests2.3. Basic Usage
python
from DrissionPage import ChromiumPage
# Create browser instance
page = ChromiumPage()
# Navigate to URL
page.get('https://wikipedia.org')
# Find and interact with elements
page('#search-input').input('Hello World')
page('#submit-btn').click()3. What is CapSolver?
CapSolver is an AI-powered automatic CAPTCHA solving service that supports a wide range of CAPTCHA types. It provides a simple API that allows you to submit CAPTCHA challenges and receive solutions within seconds.
3.1. Supported CAPTCHA Types
- Cloudflare Turnstile - The most common modern anti-bot challenge
- Cloudflare Challenge
- reCAPTCHA v2 - Image-based and invisible variants
- reCAPTCHA v3 - Score-based verification
- AWS WAF - Amazon Web Services CAPTCHA
- And many more...
3.2. Getting Started with CapSolver
- Sign up at capsolver.com
- Add funds to your account
- Get your API key from the dashboard
3.3. API Endpoints
- Server A:
https://api.capsolver.com - Server B:
https://api-stable.capsolver.com
4. Pre-Integration Challenges
Before combining DrissionPage with CapSolver, web automation faced several pain points:
| Challenge | Impact |
|---|---|
| WebDriver detection | Selenium scripts blocked immediately |
| CAPTCHA challenges | Manual solving required, breaking automation |
| iframe complexity | Difficult to interact with nested content |
| Multi-tab operations | Required complex tab switching logic |
The DrissionPage + CapSolver integration solves all these challenges in one workflow.
5. Integration Methods
5.1. API Integration (Recommended)
The API integration approach gives you full control over the CAPTCHA solving process and works with any CAPTCHA type.
5.1.1. Setup Requirements
bash
pip install DrissionPage requests5.1.2. Core Integration Pattern
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def create_task(task_payload: dict) -> str:
"""Create a CAPTCHA solving task and return the task ID."""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": task_payload
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"CapSolver error: {result.get('errorDescription')}")
return result["taskId"]
def get_task_result(task_id: str, max_attempts: int = 120) -> dict:
"""Poll for task result until solved or timeout."""
for _ in range(max_attempts):
response = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]
elif result.get("status") == "failed":
raise Exception(f"Task failed: {result.get('errorDescription')}")
time.sleep(1)
raise TimeoutError("CAPTCHA solving timed out")
def solve_captcha(task_payload: dict) -> dict:
"""Complete CAPTCHA solving workflow."""
task_id = create_task(task_payload)
return get_task_result(task_id)5.2. Browser Extension
You can also use the CapSolver browser extension with DrissionPage for a more hands-off approach.
5.2.1. Installation Steps
- Download the CapSolver extension from capsolver.com/en/extension
- Extract the extension files
- Configure your API key in the extension's
config.jsfile:
javascript
// In the extension folder, edit: assets/config.js
var defined = {
apiKey: "YOUR_CAPSOLVER_API_KEY", // Replace with your actual API key
enabledForBlacklistControl: false,
blackUrlList: [],
enabledForRecaptcha: true,
enabledForRecaptchaV3: true,
enabledForTurnstile: true,
// ... other settings
}- Load it into DrissionPage:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.add_extension('/path/to/capsolver-extension')
page = ChromiumPage(co)
# The extension will automatically detect and solve CAPTCHAsNote: The extension must have a valid API key configured before it can solve CAPTCHAs automatically.
6. Code Examples
6.1. Solving Cloudflare Turnstile
Cloudflare Turnstile is one of the most common CAPTCHA challenges. Here's how to solve it:
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_turnstile(site_key: str, page_url: str) -> str:
"""Solve Cloudflare Turnstile and return the token."""
# Create the task
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"Error: {result.get('errorDescription')}")
task_id = result["taskId"]
# Poll for result
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
elif result.get("status") == "failed":
raise Exception(f"Failed: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
turnstile_site_key = "0x4XXXXXXXXXXXXXXXXX" # Find this in page source
# Create browser instance
page = ChromiumPage()
page.get(target_url)
# Wait for Turnstile to load
page.wait.ele_displayed('input[name="cf-turnstile-response"]', timeout=10)
# Solve the CAPTCHA
token = solve_turnstile(turnstile_site_key, target_url)
print(f"Got Turnstile token: {token[:50]}...")
# Inject the token using JavaScript
page.run_js(f'''
document.querySelector('input[name="cf-turnstile-response"]').value = "{token}";
// Also trigger the callback if present
const callback = document.querySelector('[data-callback]');
if (callback) {{
const callbackName = callback.getAttribute('data-callback');
if (window[callbackName]) {{
window[callbackName]('{token}');
}}
}}
''')
# Submit the form
page('button[type="submit"]').click()
page.wait.load_start()
print("Successfully bypassed Turnstile!")
if __name__ == "__main__":
main()6.2. Solving reCAPTCHA v2 (Auto-Detect Site Key)
This example automatically detects the site key from the page - no manual configuration needed:
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v2(site_key: str, page_url: str) -> str:
"""Solve reCAPTCHA v2 and return the token."""
# Create the task
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"Error: {result.get('errorDescription')}")
task_id = result["taskId"]
print(f"Task created: {task_id}")
# Poll for result
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"Failed: {result.get('errorDescription')}")
time.sleep(1)
def main():
# Just provide the URL - site key will be auto-detected
target_url = "https://www.google.com/recaptcha/api2/demo"
# Configure browser
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
print("Starting browser...")
page = ChromiumPage(co)
try:
page.get(target_url)
time.sleep(2)
# Auto-detect site key from page
recaptcha_div = page('.g-recaptcha')
if not recaptcha_div:
print("No reCAPTCHA found on page!")
return
site_key = recaptcha_div.attr('data-sitekey')
print(f"Auto-detected site key: {site_key}")
# Solve the CAPTCHA
print("Solving reCAPTCHA v2...")
token = solve_recaptcha_v2(site_key, target_url)
print(f"Got token: {token[:50]}...")
# Inject the token
page.run_js(f'''
var responseField = document.getElementById('g-recaptcha-response');
responseField.style.display = 'block';
responseField.value = '{token}';
''')
print("Token injected!")
# Submit the form
submit_btn = page('#recaptcha-demo-submit') or page('input[type="submit"]') or page('button[type="submit"]')
if submit_btn:
submit_btn.click()
time.sleep(3)
print("Form submitted!")
print(f"Current URL: {page.url}")
print("SUCCESS!")
finally:
page.quit()
if __name__ == "__main__":
main()Test it yourself:
bash
python recaptcha_demo.pyThis will open Google's reCAPTCHA demo page, automatically detect the site key, solve the CAPTCHA, and submit the form.
6.3. Solving reCAPTCHA v3
reCAPTCHA v3 is score-based and doesn't require user interaction. You need to specify the action parameter.
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v3(
site_key: str,
page_url: str,
action: str = "verify",
min_score: float = 0.7
) -> str:
"""Solve reCAPTCHA v3 with specified action and minimum score."""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
"pageAction": action,
"minScore": min_score
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"Error: {result.get('errorDescription')}")
task_id = result["taskId"]
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"Failed: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
recaptcha_v3_key = "6LcXXXXXXXXXXXXXXXXXXXXXXXXX"
# Setup headless browser for v3
co = ChromiumOptions()
co.headless()
page = ChromiumPage(co)
page.get(target_url)
# Solve reCAPTCHA v3 with "search" action
print("Solving reCAPTCHA v3...")
token = solve_recaptcha_v3(
recaptcha_v3_key,
target_url,
action="search",
min_score=0.9 # Request high score
)
# Execute the callback with the token
page.run_js(f'''
// If there's a callback function, call it with the token
if (typeof onRecaptchaSuccess === 'function') {{
onRecaptchaSuccess('{token}');
}}
// Or set the hidden field value
var responseField = document.querySelector('[name="g-recaptcha-response"]');
if (responseField) {{
responseField.value = '{token}';
}}
''')
print("reCAPTCHA v3 bypassed!")
if __name__ == "__main__":
main()6.4. Using Action Chains for Human-Like Behavior
DrissionPage's action chains provide natural mouse movements and keyboard interactions:
python
import time
import random
from DrissionPage import ChromiumPage
from DrissionPage.common import Keys, Actions
def human_delay():
"""Random delay to mimic human behavior."""
time.sleep(random.uniform(0.5, 1.5))
def main():
page = ChromiumPage()
page.get('https://your-target-site.com/form')
# Use action chains for human-like interactions
ac = Actions(page)
# Move to input field naturally, then click and type
ac.move_to('input[name="email"]').click()
human_delay()
# Type slowly like a human
for char in "user@email.com":
ac.type(char)
time.sleep(random.uniform(0.05, 0.15))
human_delay()
# Move to password field
ac.move_to('input[name="password"]').click()
human_delay()
# Type password
page('input[name="password"]').input("mypassword123")
# After solving CAPTCHA, click submit with natural movement
ac.move_to('button[type="submit"]')
human_delay()
ac.click()
if __name__ == "__main__":
main()7. Best Practices
7.1. Browser Configuration
Configure DrissionPage to appear more like a regular browser:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
co.set_argument('--no-sandbox')
co.set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# Set window size to common resolution
co.set_argument('--window-size=1920,1080')
page = ChromiumPage(co)7.2. Incognito and Headless Modes
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.incognito() # Use incognito mode
co.headless() # Run headless (for v3 CAPTCHAs)
page = ChromiumPage(co)7.3. Rate Limiting
Avoid triggering rate limits by adding random delays:
python
import random
import time
def human_delay(min_sec=1.0, max_sec=3.0):
"""Random delay to mimic human behavior."""
time.sleep(random.uniform(min_sec, max_sec))
# Use between actions
page('#button1').click()
human_delay()
page('#input1').input('text')7.4. Error Handling
Always implement proper error handling for CAPTCHA solving:
python
def solve_with_retry(task_payload: dict, max_retries: int = 3) -> dict:
"""Solve CAPTCHA with retry logic."""
for attempt in range(max_retries):
try:
return solve_captcha(task_payload)
except TimeoutError:
if attempt < max_retries - 1:
print(f"Timeout, retrying... ({attempt + 1}/{max_retries})")
time.sleep(5)
else:
raise
except Exception as e:
if "balance" in str(e).lower():
raise # Don't retry balance errors
if attempt < max_retries - 1:
time.sleep(2)
else:
raise7.5. Proxy Support
Use proxies with DrissionPage for IP rotation:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_proxy('http://username:password@proxy.example.com:8080')
page = ChromiumPage(co)8. Conclusion
The integration of DrissionPage and CapSolver creates a powerful toolkit for web automation:
- DrissionPage handles browser automation without WebDriver detection signatures
- CapSolver handles CAPTCHAs with AI-powered solving
- Together they enable seamless automation that appears fully human
Whether you're building web scrapers, automated testing systems, or data collection pipelines, this combination provides the reliability and stealth you need.
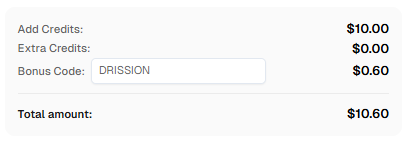
Bonus: Use code
DRISSIONwhen signing up at CapSolver to receive bonus credits!
9. FAQ
9.1. Why choose DrissionPage over Selenium?
DrissionPage doesn't use WebDriver, which means:
- No need to download/update chromedriver
- Avoids common WebDriver detection signatures
- Simpler API with built-in waits
- Better performance and resource usage
- Native support for cross-iframe element location
9.2. Which CAPTCHA types work best with this integration?
CapSolver supports all major CAPTCHA types. Cloudflare Turnstile and reCAPTCHA v2/v3 have the highest success rates. The integration works seamlessly with any CAPTCHA that CapSolver supports.
9.3. Can I use this in headless mode?
Yes! DrissionPage supports headless mode. For reCAPTCHA v3 and token-based CAPTCHAs, headless mode works perfectly. For v2 visible CAPTCHAs, headed mode may provide better results.
9.4. How do I find the site key for a CAPTCHA?
Look in the page source for:
- Turnstile:
data-sitekeyattribute orcf-turnstileelements - reCAPTCHA:
data-sitekeyattribute ong-recaptchadiv
9.5. What if CAPTCHA solving fails?
Common solutions:
- Verify your API key and balance
- Ensure the site key is correct
- Check that the page URL matches where the CAPTCHA appears
- For v3, try adjusting the action parameter and minimum score
- Implement retry logic with delays
9.6. Can DrissionPage handle shadow DOM?
Yes! DrissionPage has built-in support for shadow DOM elements through the ChromiumShadowElement class.
More
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
Learn scalable Rust web scraping architecture with reqwest, scraper, async scraping, headless browser scraping, proxy rotation, and compliant CAPTCHA handling.
Web ScrapingApr 17, 2026
How to Scrape Job Listings Without Getting Blocked
Learn the best techniques to scrape job listings without getting blocked. Master Indeed scraping, Google Jobs API, and web scraping API with CapSolver.
